
Book analysis with AI techniques
This learning sequence explores text analysis through Natural Language Processing, a significant application of Artificial Intelligence. Teachers and students are led through a series of video tutorials to develop a Python program that can break down and analyse the content of a complete text and use smart sentiment analysis to attempt to determine the villain(s) and hero(s).
Additional details
| Year band(s) | 7-8, 9-10 |
|---|---|
| Content type | Lesson ideas, Course or tutorial |
| Format | Web page |
| Core and overarching concepts | Specification (decomposing problems), Computational thinking, Implementation (programming) |
| Australian Curriculum Digital Technologies code(s) |
AC9TDI8P02
Analyse and visualise data using a range of software, including spreadsheets and databases, to draw conclusions and make predictions by identifying trends
AC9TDI8P04
Define and decompose real-world problems with design criteria and by creating user stories
AC9TDI8P07
Design the user experience of a digital system
AC9TDI8P08
Generate, modify, communicate and evaluate alternative designs
AC9TDI8P05
Design algorithms involving nested control structures and represent them using flowcharts and pseudocode
AC9TDI8P06
Trace algorithms to predict output for a given input and to identify errors
AC9TDI10P02
Analyse and visualise data interactively using a range of software, including spreadsheets and databases, to draw conclusions and make predictions by identifying trends and outliers
AC9TDI10P04
Define and decompose real-world problems with design criteria and by interviewing stakeholders to create user stories
AC9TDI10P07
Design and prototype the user experience of a digital system
AC9TDI10P10
Evaluate existing and student solutions against the design criteria, user stories, possible future impact and opportunities for enterprise
AC9TDI10P05
Design algorithms involving logical operators and represent them as flowcharts and pseudocode
AC9TDI10P09
Implement, modify and debug modular programs, applying selected algorithms and data structures, including in an object-oriented programming language |
| Technologies & Programming Languages | Artificial Intelligence, Python |
| Keywords | Programming, Coding, Data representation, Jason Vearing, Nathan Alison, Python, flowchart, variables, loops, Chatbot |
| Integrated, cross-curriculum, special needs | English |
| Organisation | ESA |
| Copyright | Creative Commons Attribution 4.0, unless otherwise indicated. |
Related resources
-

Python language
Students develop and implement digital solutions using Python programming language through applying data types and control structures.
-

Emerging technologies
Students follow a problem-solving process to develop an idea for applying emerging technologies to improve existing digital systems.
-

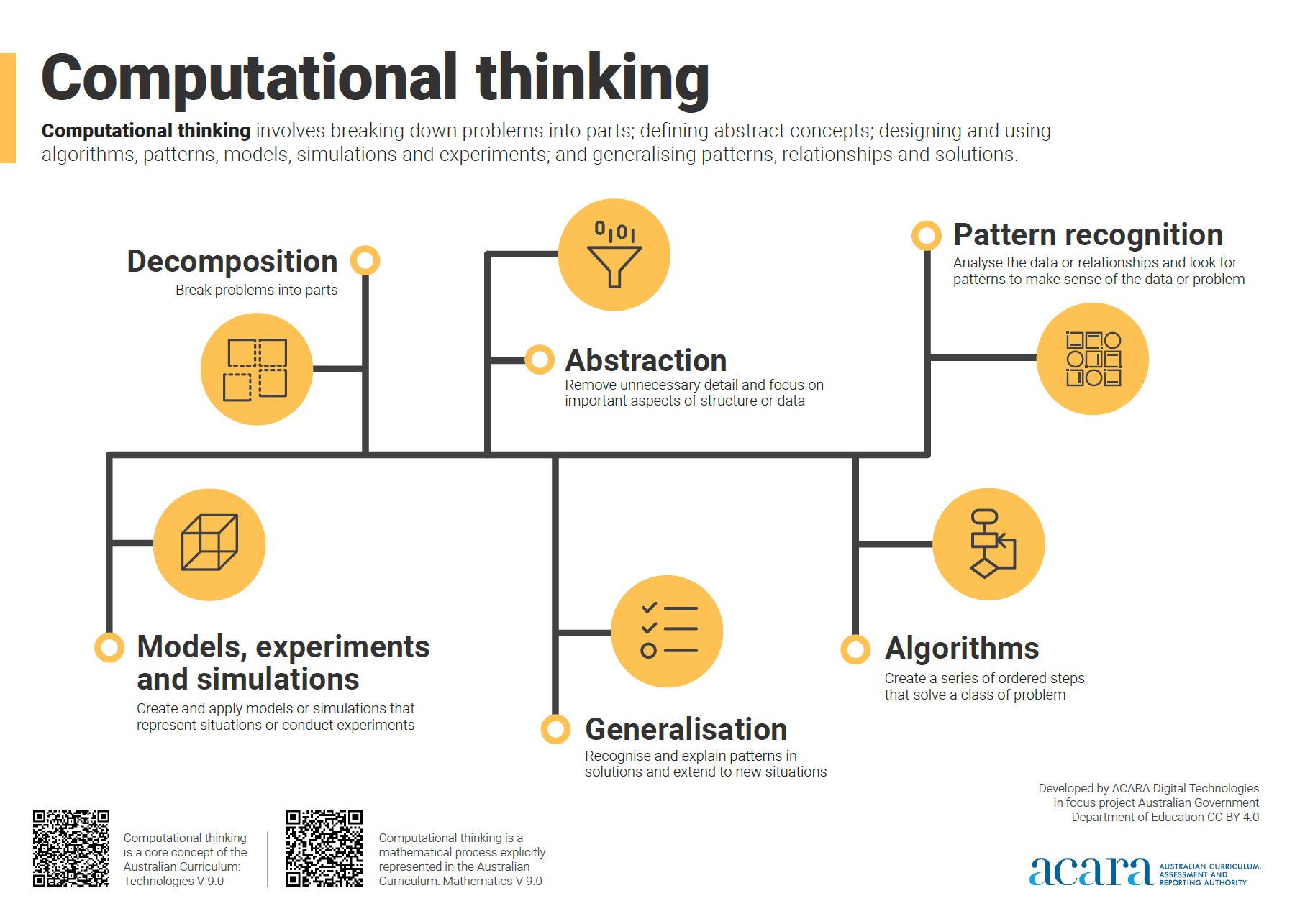
Computational thinking poster
A poster/infographic that gives a brief overview of the concepts related to computational thinking.
-
Codecademy
This site provides tutorials on web design tools. Requires free registration.
-

App Inventor EDU
Use this six week teaching program using a project based curriculum that allows students to explore the world of computer science through the creation of smartphone apps.
-

Classroom ideas: Micro:bit Environmental Measurement (visual and general-purpose programming) (Years 5-8)
Investigating environmental data with Micro:bits: This tutorial shows the coding needed for digital solutions of some environmental issues that can be created using pseudocode and visual programming.
-

Creating a digital start line and finish line with micro:bits (Years 7-8)
The following activity suggests one-way Digital Technologies could be integrated into a unit where vehicles are being designed and produced.
-

code.org
Code.org provides courses for F-12 year levels to increase knowledge in computer science. Free log in enables access to resources and more functionality.
{kind=link}